論文メモ:Attention Is All You Need
Googleが昨年発表した,BERT:Bidirectional Encoder Representation for Transformersは,様々なNLPタスクにおいて当時の最高スコアを記録し,世界中で瞬く間に注目を浴びることとなりました.結果として,BERTはNAACL 2019のBest Long Paper Awardにも輝いています.
ここでは,そんなBERTの基本構成要素となっている,Transformerについての論文メモを共有します.
文献情報
著者: A. Vaswani et al.
所属: Google Brain
出典: NeurIPS 2017
どんなもの?
Attentionをフルに活用した系列変換モデルを提案した.
先行研究と比べてどこがすごい?
- 再帰や畳み込みを用いない新しい系列変換(sequence transduction)モデルを提案した.
→ 並列処理が可能となり,計算コストを削減したことで,学習時間を大幅に減らすことができた.
→ 英独・英仏の翻訳テストで当時の最高スコア: BLEUを記録した.
技術や手法のキモはどこ?
-
ほぼAttention(注意機構)だけを用いて系列変換モデルを構築している点
→ Scaled Dot-Product Attention
→ Multi-Head Attention -
時系列を考慮するために,位置エンコーディング(positional encoding)を導入している点
どうやって有効だと検証した?
- 主にBLEUスコアとパープレキシティ
- 構文解析のスコア


論文の主張
近年の系列変換モデルは,再帰ニューラルネットや畳込みニューラルネットに大きく依存している.また,SoTAを達成するようなモデルであっても,注意機構を取り入れた再帰 or CNNのモデルに依存しており,モデルが複雑になっている.
この論文では,Transformerと呼ばれる,注意機構にだけ基づくシンプルなモデルを提案している.Transformerは再帰ニューラルネットや畳み込みニューラルネットを必要としないモデルである.
実験結果では,翻訳タスクについてstate-of-the-artを達成し,かつその並列演算能力の高さや,学習時間の低減というメリットが挙げられた.また,翻訳タスク以外のNLPタスクへの有用性も示唆された.
従来手法
時系列モデリングにおける再帰ニューラルネット & 畳み込みを用いたモデルは,これまで多く活用されてきた.
- 再帰を伴うモデルは実行時間にかなりの影響を及ぼす.
→ 再帰によって並列計算が妨げられるため.
→ factorization trickやconditional computationといった手法が考案されてきた.- こうした手法は直接的に時系列モデリングの問題を解決するものではない.
- こうした手法は直接的に時系列モデリングの問題を解決するものではない.
- 畳み込みを伴うモデルは再帰よりも実行時間に影響は及ぼさない.
- しかし,入出力の依存関係を計算する際に,その範囲が大きくなればなるほど,計算量が対数または,線形に増加してしまうというデメリットがある.
- しかし,入出力の依存関係を計算する際に,その範囲が大きくなればなるほど,計算量が対数または,線形に増加してしまうというデメリットがある.
- 注意機構は時系列モデリングにおいて広く用いられてきた.
→ 注意機構を用いることで,依存関係のモデリングが可能となる.
提案手法の先行研究との違い
- 新たに提唱するTransformerは,Attentionだけを活用し,再帰は一切伴わない.
→ Attentionが入力と出力間の大域的な依存関係を抽出できる.
→ 並列計算が可能となり,計算の高速化が図られる.
→ 翻訳の質の観点においても,SoTAを達成することができた.
Attentionについて
- Attentionの算出方法には次の二つが挙げられる.
-
Additive Attention: 加法注意機構 隠れ層が一つのフィードフォワードネットワークを用いてAttentionを計算する.
-
Dot-product Attention: 内積注意機構 論文中で使われているAttentionである.行列を用いてAttentionが計算できるため,高速性・省メモリ性に優れている.
-
- self-attention: 自己注意機構
単一のシーケンスに対してattentionを適用する手法のこと.Encoder-Decoderモデルで用いられるattentionとは異なる.
→ 入力文の特徴量を抽出するために使われる.
→ Transformerで使われるAttetionはSelf-attention.
提案手法
- モデルは基本的な系列変換モデルの枠組みに基づく.
→ つまり,各時刻において,モデルは自己回帰を行う.- ここでの自己回帰は,次のトークンを生成するために,前に生成されたトークンを追加の入力として用いるということである.
- ここでの自己回帰は,次のトークンを生成するために,前に生成されたトークンを追加の入力として用いるということである.
- モデルは,スタック型自己注意と全結合層(point-wise)からなる.
→ 以下の図がモデルの概要図になっている.
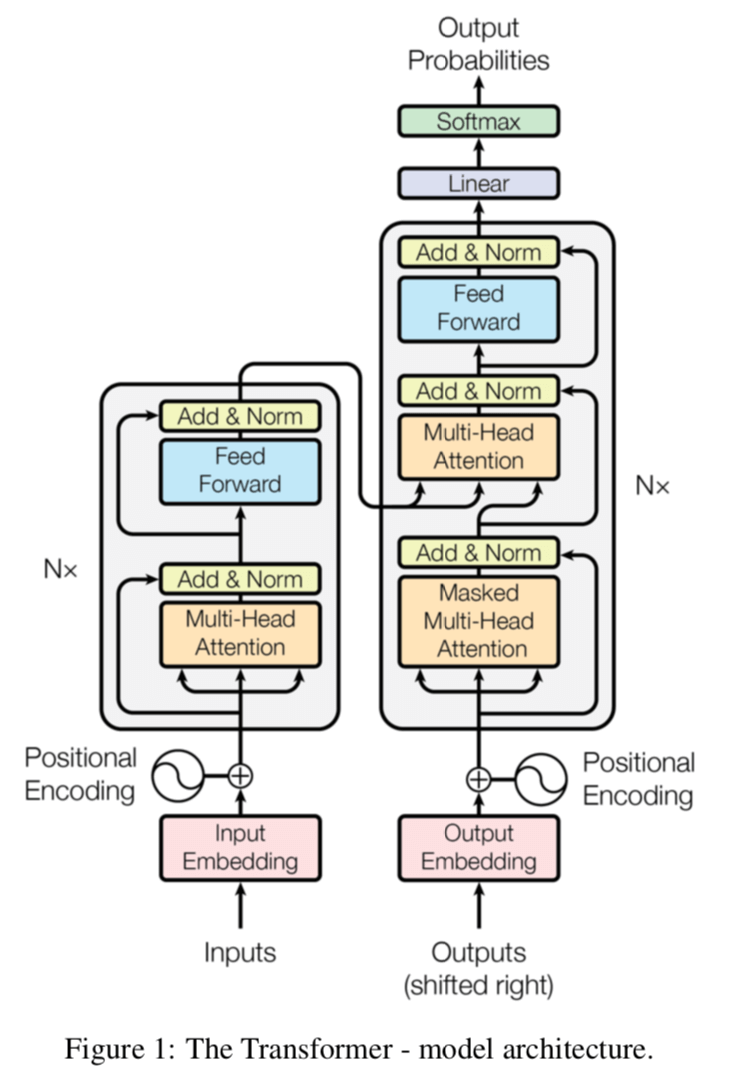
1. エンコーダスタック
-
エンコーダネットワークはスタック型となっており,6個のブロックから構成される.
→ この6はハイパーパラメータ. - ブロック内での処理の流れ(順方向)
- multi-head self-attentionを適用する.
- 残差接続のベクトル(つまり入力ベクトル)と1の出力ベクトルを足し合わせて,層正規化を行う.
- 位置ごとの全結合を適用する.
- 残差接続のベクトル(つまり2の出力ベクトル)と3の出力ベクトルを足し合わせて,層正規化を行う.
- 各層の次元は512で統一されている.
- 残差接続は単に勾配消失を防いで学習をうまく進めるためと思われる.
- 層正規化は学習時間の軽減&学習の安定化に寄与する.
- BERTはこのエンコーダ部分を活用している.
参照: (層正規化の論文)
2. デコーダスタック
-
デコーダネットワークも6個の独立したスタックブロックから構成される.
-
エンコーダネットワークにある2層に加えて,エンコーダの出力を活用したmulti-head attentionを追加している.
-
Self-attentionに関しては,未来の入力を考慮することがないように,マスク付きに改良している.
→ 予測対象の単語の情報が事前に漏れるのを防ぐ目的
3. Attention
- Attentionはクエリとキー&バリューの組を出力ベクトルにマッピングするものと捉えることができる.
→ 出力ベクトルはバリューの重みつき線形和で表される.
→ 重みは,クエリとキーの変換関数から算出される.
3.1 スケール化内積注意
- 論文内で使用されるattentionは基本的に,スケール化内積注意(Scaled Dot-Product Attention)を用いている.
-
入力は次元: $d_k$のクエリとキー,次元: $d_v$のバリューからなる.
- Attentionの計算手順は以下のようになる
- あるクエリに対して,そのクエリと全てのキーの内積を求める.
- $\sqrt{d_k}$で除算する.(スケール化)
- ソフトマックスにかけることで,各バリューの重みを求める.
- バリューと重みを掛け合わせる.
- 実際には,複数のクエリを同時に処理するため,行列を用いて以下のように求められる.
- $d_k$ が小さいときは内積注意も加法注意も実行時間に変わりはないが,$d_k$ が大きくなるにつれて,加法注意の方が高速になってしまう.
→ 内積が大きくなるので,勾配が極端に小さくなり,学習が進まなくなる.
→ これに対処するために,スケール化を行う.
3.2 Multi-head attention
- multi-head attentionは,attentionを複数に分割することを意味する.
→ モデルが異なる部分空間から異なる情報を抽出するのに長けている.
→ いろいろなnグラムを取る目的と一緒.
→ イメージとしてはCNNでチャンネル数を増やしてモデルの表現力を高めることと同じ?
ただし,$W_i^Q, W_i^K \in \mathbb{R}^{d_{model} \times d_k}$, $W_i^V \in \mathbb{R}^{d_{model} \times d_v}$, $W^O \in \mathbb{R}^{hd_v \times d_{model}}$ である.
論文中では,$h = 8$, $d_k = d_v = d_{\rm model} / h = 64$ なので,各ヘッドの次元が小さくなるため,計算量的にはsingle-head attentionとあまり変わらなくなる.
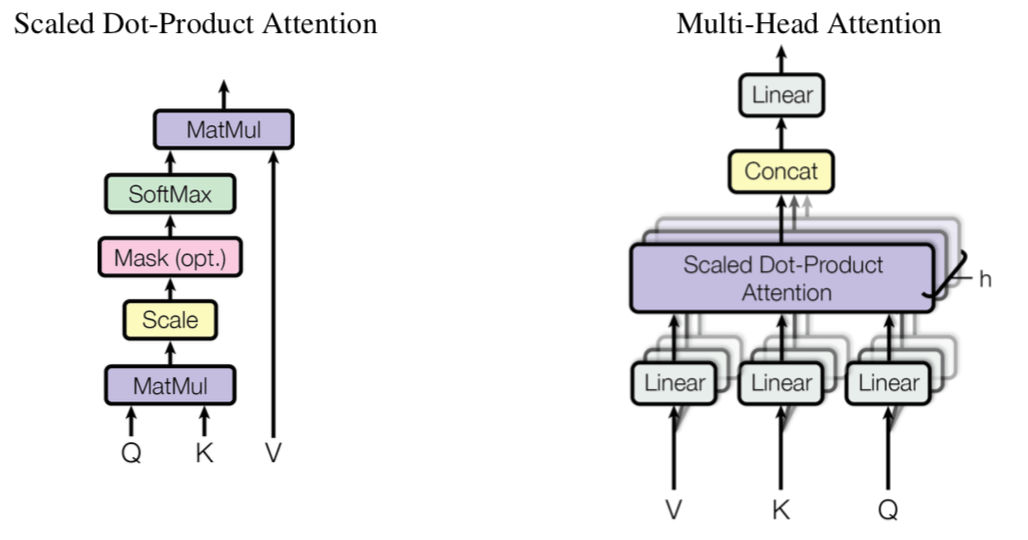
3.3 TransformerにおけるAttention
-
デコーダの「エンコーダ・デコーダ」Attention
→ クエリは前のデコーダの出力
→ キーとバリューはエンコーダの出力
つまり,普通の系列変換モデルでのattentionと同様である. -
エンコーダのAttention
→ 単純な自己注意
→ クエリ,キー,バリューともに前のエンコーダの出力 -
デコーダのAttention
→ 自分のポジションまで参照できる自己注意
→ 自己回帰がきちんとできるようにするため
→ 図2中で,スケール化内積注意のsoftmax前に,未来の入力に対応する部分を,$-\infty$で置き換えることにより,実装した.
→ ${\rm softmax}(x_i)=\frac{\exp(x_i)}{\sum_j \exp (x_j)}$で,$x_i \to -\infty$なら,その項は0になるので,考慮されなくなるということ.
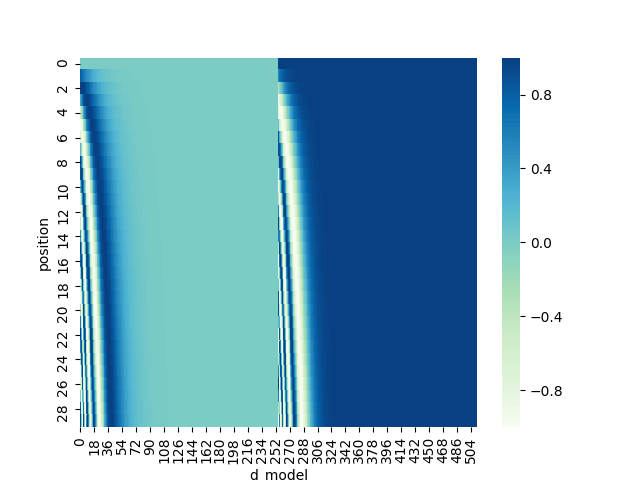
4. 位置エンコーディング
- Transformerは畳み込みや再帰を伴わないので,それだけでは時系列を考慮することができない.
→ 時系列を考慮するために,入力の埋め込み表現に「位置情報」を埋め込む.
評価指標
BLEU
Bilingual Evaluation Understudyの略.
ACL2002で発表された機械翻訳の自動評価指標である.
BLEUスコアは高ければ高いほどよい指標となっている.
BPとは?
BPとは,brevity penaltyの略.brevityは英語で「簡潔さ・短さ」を意味する.
つまり,翻訳された結果が短文であると,その文だけペナルティを喰らうということである.
修正Nグラムだけでは,翻訳文が短い文のときに$P_n$が高くなってしまうため,このBP項で低減させる.
ただし,$c$は翻訳された文の長さを意味し,$r$は正解コーパス中の対応する文の長さである.
修正Nグラム精度とは?
- $\left(\sum_{n=1}^N \frac{1}{N} \log P_n \right)$において,
- $N$はNグラムの最大長(英語だと4が多いらしい)
- $P_n$はNグラム精度を表している.
- Nグラム精度は,翻訳文とコーパスの参照文がどれだけ一致するかを数値化したものである.
詳しくは長ったらしくなるので,論文本体を参照.
実験・解析結果
計算コスト比較
通常,シーケンスの長さ $n$ は,モデルの次元 $d$ よりも小さいことが多いので, $n < d$ で,Self-Attentionの計算量コストが最も小さくなる.

Complexity per layer
1層あたりの計算量を意味する.
-
Self-Attentionの場合
Self-Attentionの重み算出式は,${\rm softmax}(QK^{T}) V$ である.分解して考えていくと,まず,$QK^{T}$ は,$(n \times d)$ と $(d \times n)$ の行列の積であるから,$O(n^2d)$ である.続いて,${\rm softmax}$ の計算量は,ひとつの要素を計算するのに,$O(n)$ かかるので,$n$ 個の要素を考えると $O(n) \times n$ で,$O(n^2)$ である.最後に,${\rm softmax}(QK^{T})$ と,$V$ の行列の積は,$QK^{T}$ と同じく $O(n^2d)$ となる.
したがって,これらを合計すると,$O(n^2d) + O(n^2) + O(n^2d)$ であり,$O(n^2d)$ とまとめることができる.ゆえに,Self-Attentionの層あたりの計算量は,$O(n^2d)$ となる.
-
Recurrentの場合
Recurrentの時刻 $t$ における隠れ層の重み算出式は,$\mathbf{h_t} = \tanh \left(\mathbf{h_{t-1}} W + \mathbf{x_t} U + \mathbf{b} \right)$ と表せる.なお,活性化関数は $\tanh$ に限らず,シグモイド関数のときもある.いずれにせよ,どちらの手法も定数時間で処理できるので,ここでは $\tanh$ を活性化関数として使う.Self-Attentionと同様に,分解して考えていくと,まず,$\mathbf{h_{t-1}} W$ は,$(1 \times d)$ と $(d \times d)$ の行列積であるから,$O(d^2)$ である.続いて,$\mathbf{x_t} U$ は,$(1 \times d)$ と $(d \times d)$ の行列積であるので,$O(d^2)$ である.また,行列和については,サイズが $(1 \times d)$ 同士の和であるので,$O(d)$ である.最後に,$\tanh (x) = \frac{\exp(x) - \exp(-x)}{\exp(x) + \exp(-x)}$ の計算量は,$d$ 個の要素に対して適用するので,$O(d)$である.
したがって,時刻 $t$における計算量は,$O(d^2) + O(d^2) + O(d) + O(d)$ で,$O(d^2)$ とまとめられる.入力シーケンスの長さは,$n$ であるから,層あたりの計算量は $O(d^2) \times n$ で, $O(nd^2)$ となる.
-
Convolutionの場合
Convolutionでの重みは,「カーネルサイズ * 入力のチャンネル数(特徴マップの数)* 出力のチャンネル数 + 出力チャンネルごとのバイアス」 で求まるので,図中の変数を代入して計算すると,$O(k \times d \times d)$ となる.バイアスは定数項とみなせるので無視できる.したがって,$n$ 個の要素について考えるので,$O(kd^2) \times O(n) = O(knd^2)$ となる.
Sequential Operations
逐次処理を最小限にする並列処理可能な計算量のこと.Recurrent層はシーケンスの長さだけコストがかかるのは直感的である.
Maximum Path Length
ネットワーク内の長距離依存関係間の経路長のこと. Self-Attentionは定数のコストで,入出力間の任意の組み合わせの経路を繋げることができる.一方で,再帰が$O(n)$であり,畳み込みが$O(\log n)$であることは,簡単にBackgroundで触れられていた気がする.
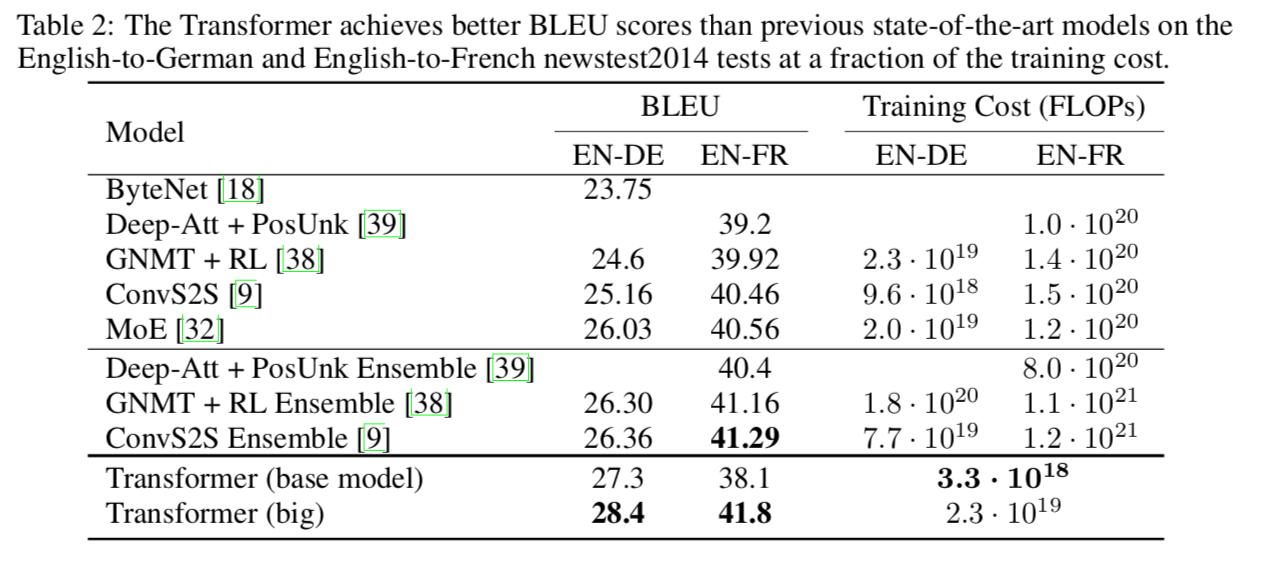
翻訳性能比較
表から,Transformerは高い翻訳精度を出しつつ,かつ計算コストを削減できていることがわかる.
実装
時系列を考慮するために提案された手法:Positional Encoding(位置エンコーディング)を可視化するスクリプトを書きました.
GitHub に置いてあります.ご自由にご利用ください.