論文メモ:Decoupling Strategy and Generation in Negotiation Dialogues
本稿では,EMNLP 2018に採択された,自然言語で売り物の価格交渉をするエージェントを提案した論文:「Decoupling Strategy and Generation in Negotiation Dialogues」の論文のメモ書きを共有・紹介します.
文献情報
著者: H. He et al.
所属: Computer Science Department, Stanford University
出典: EMNLP 2018
どんなもの?
自然言語で交渉可能なエージェントを作成する際に,交渉戦略とその実行部(発話機構)を切り分けて考えることで,従来手法よりもタスクの合意成功率を向上させ,発話に見られる人間らしさを向上させることに成功した.
先行研究と比べてどこがすごい?
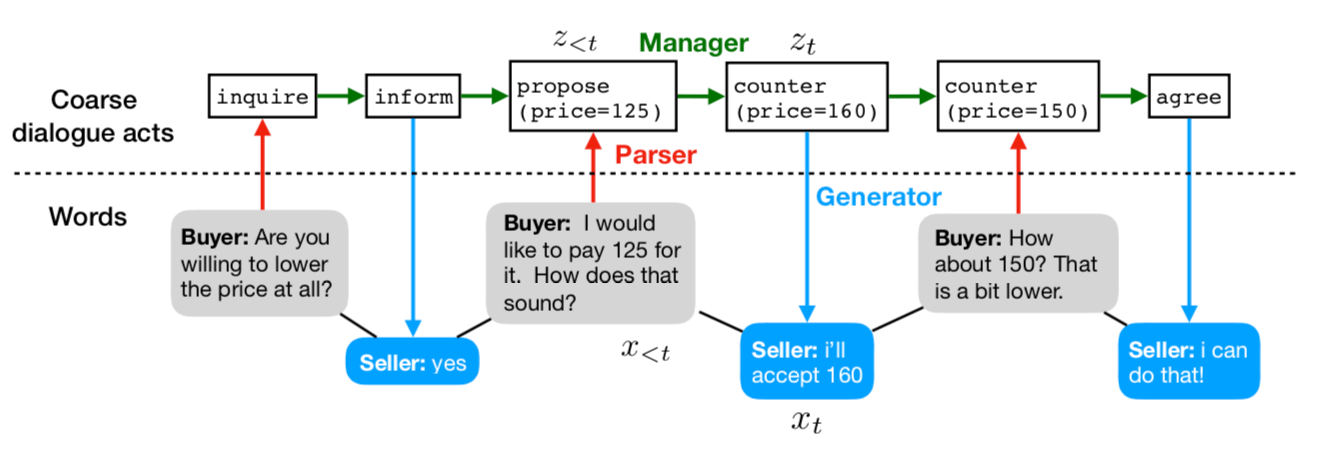
単にend-to-endでモデルを学習させるのではなく,「Parser・Manager・Generator」の三つにモデルを分割して捉えた点.(従来手法は,seq2seqに基づいて単に学習させるだけだった.)
戦略を制御する部分は,従来の単語ベースではなく,coarse-dialogue acts:粗い(要約)対話情報に依存しているため,戦略の制御がしやすいというメリットがある.
図引用: Decoupling Strategy and Generation in Negotiation Dialogues
技術や手法のキモはどこ?
モジュール型のモデルを提案.戦略と生成を切り離して学習させることで,戦略の制御しやすさを維持しながらも,発話の人間らしさが低下しないようにできている.
どうやって有効だと検証した?
データセット
クラウドソーシングサービスである,Amazon Mechanical Turk (AMT)を活用.クレイグスリストから交渉シナリオをスクレイピングして,AMTでそのシナリオに基づいた二者間の価格交渉を行わせることで,品物売買データセットを構築.
実験
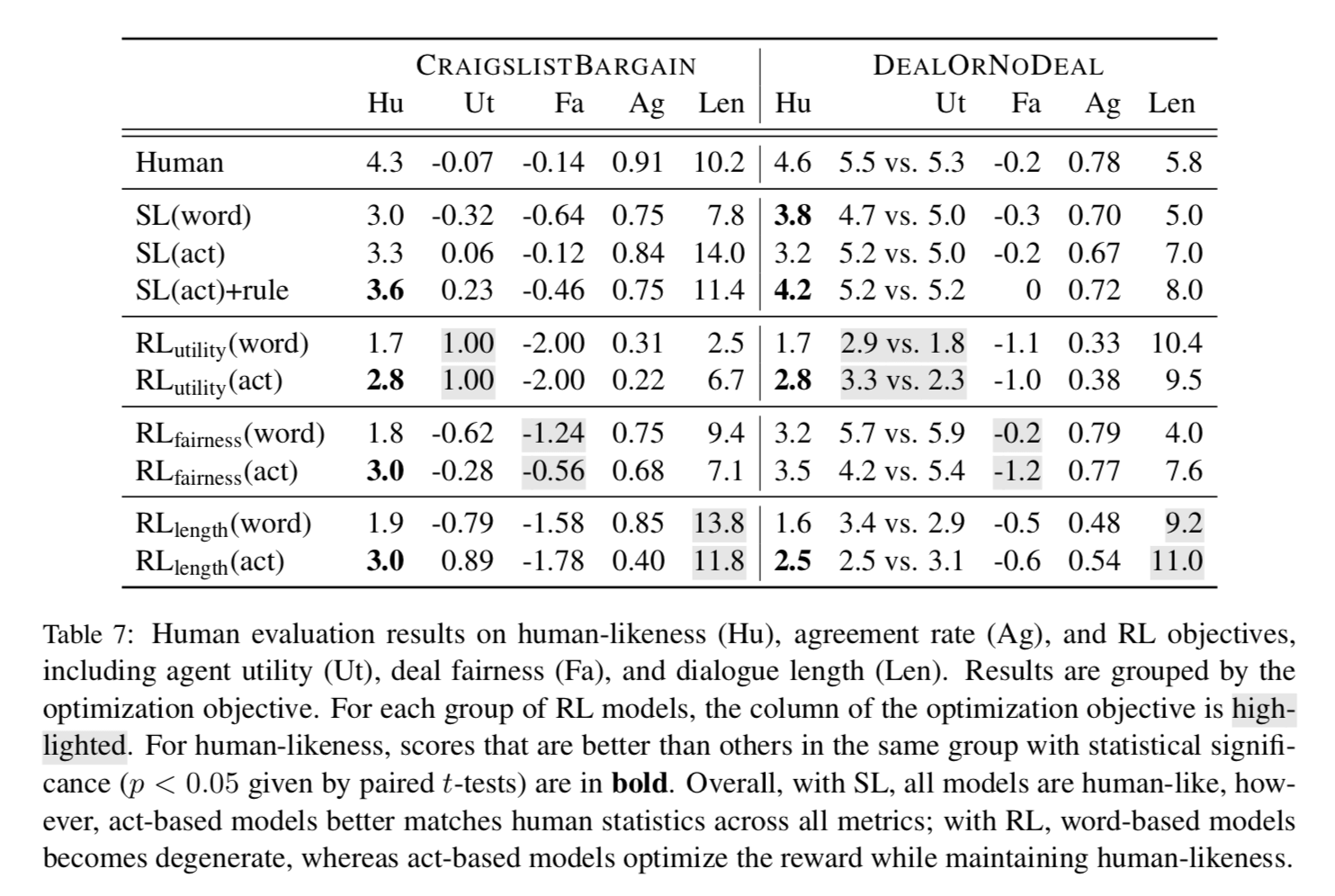
Deal or no deal データセットと,著者らが作成した,Craigslist Bargain データセットにより実験を行なっている.人間らしさを5点満点でAMT上で評価.また,task-specificな値(効用,合意率,公平さ,対話の長さ)も計算.
議論はある?
教師あり学習時は,著者の提案するモジュール型のモデルを使うとよいことが示されている.また,強化学習時も,wordベースではなくdialogue actベースにすると,報酬を最適化しつつ,発話の自然さも維持できることが示されている.


1. はじめに
交渉エージェントは以下の二つの点をうまく実行できる必要がある.
- 交渉戦略の立案
- 交渉戦略を実行するための自然言語の生成
先行研究は「戦略」に着目したものが多かった.また,近年では,end-to-endに交渉戦略と言語生成の両方を同時に,人間同士の交渉を扱ったコーパスからニューラルネットワークベースのモデルにより学習を行う研究がでてきている (Lewis 2017, He 2017).
end-to-endに学習を行うモデルの問題点として,以下が挙げられる.
- 交渉戦略の解釈 & 制御の難しさ
- 強化学習で交渉エージェントを学習させると,発話が不自然になる(例:文法に則っていない)
そこで,著者らは戦略と生成を分離する手法の提案を行なっている.これにより,同じ生成器を用いていても,戦略を変更することができる.(例:効用を最大化する・公平な合意案を導く.)
1.1 提案手法の概要
提案手法のフレームワークは三つのモジュールからなる.
-
Parser
交渉相手の発言の意図やその変数:(価格)を解析 -
Manager
交渉エージェントの次の戦略(行動)を生成 -
Generator
戦略と発話履歴を基に返答文を生成
図引用: Decoupling Strategy and Generation in Negotiation Dialogues
1.2 データセットについて
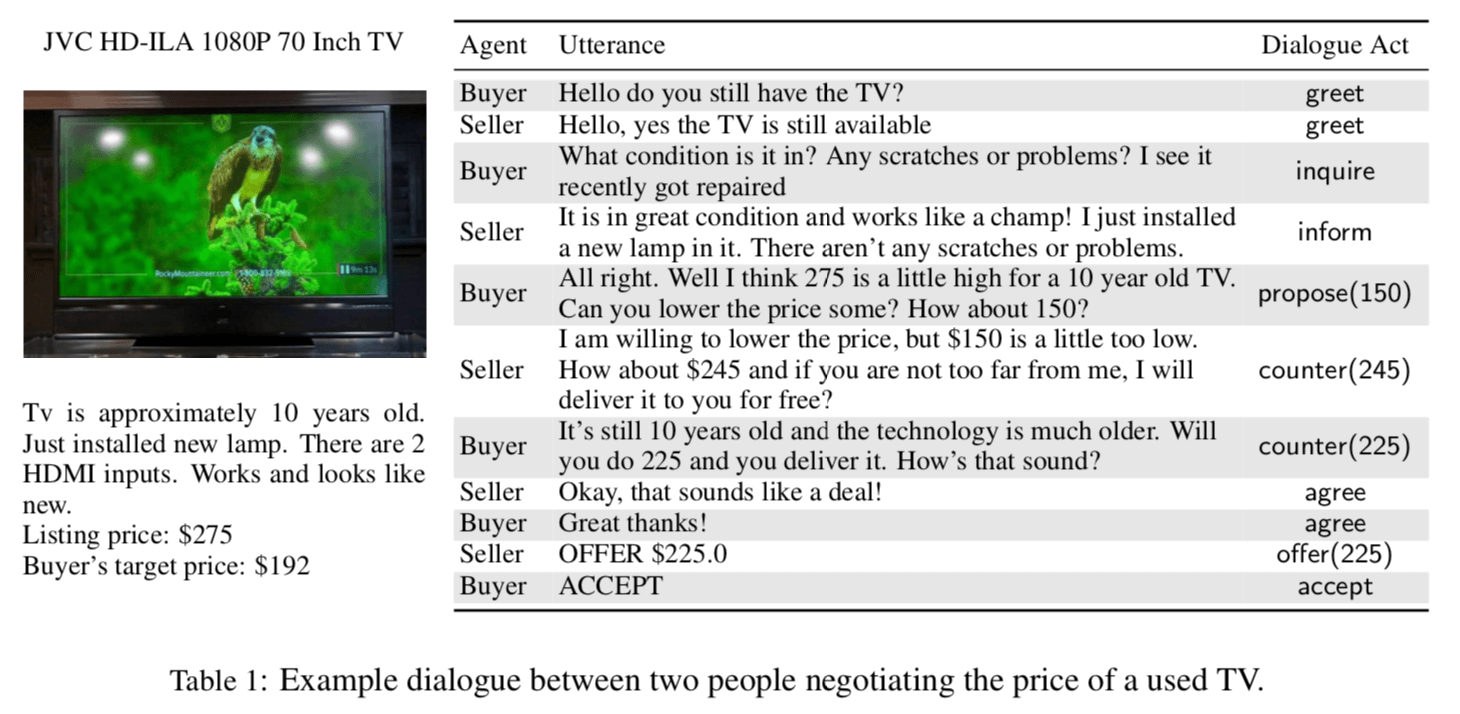
先行研究で用いられているデータセットは,クローズドなドメイン:物の山分け交渉のみを扱っている.こうした設定は,実社会(real world)とは程遠い.そのため,craigslistと呼ばれる,クラシファイドコミュニティサイトから,物の売り買いに関するポスティングを抽出して,交渉シナリオを作成した.この交渉シナリオを基に,Amazon Mechanical Turk(AMT)を活用して,二者間での物の価格交渉を実施した.この交渉ログが本論文で用いられている,Craigslist Bargain データセットである.
1.3 評価指標について
獲得効用 & 人間らしさで評価.
→ AMTを活用して,A/Bテストを行なって評価.
2. データセット
Settlers of catan データセットや,Deal or no deal データセットは,ゲーム形式の交渉対話データセットになっている.このため,対話が直接的(オファー内容をそのまま伝えてしまう)であった.本来の実社会の交渉では,「説得」や「情報収集」が入るので,先行研究のデータセットはあまり現実的でない.
クレイグスリストデータセットでは,売り手と買い手になりきって,商品の売買を行う.より自然な状況設定なので,より現実的になるという主張.
交渉シナリオの生成は,クレイグスリストの6カテゴリを選択した.(housing,furniture,cars,bikes,phones,electronics).買い手の目標価格は,リスティング価格の0.5,0.7,0.9倍で設定されている.
交渉ログの例とデータセットの統計は以下の表の通り.

図引用: Decoupling Strategy and Generation in Negotiation Dialogues
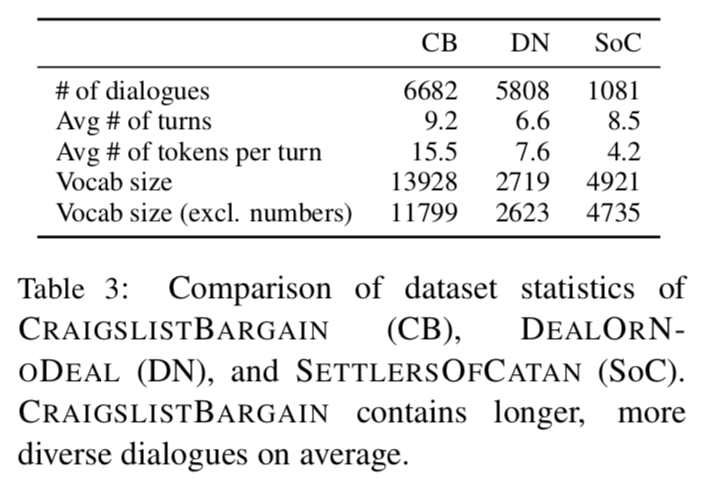
先行研究とのデータセットの比較結果は次の通り.多ジャンルのデータセットなので,語彙数が多くなっている.さらに,発話あたりの単語数も多い.
図引用: Decoupling Strategy and Generation in Negotiation Dialogues
3. Approach
- seq2seqベースのモデルは,戦略と生成の両方を同時に学習することは困難.(発話がかなり不自然になる.)
→ 戦略と生成を切り分けて考える
3.1 Overview
-
dialogue agentの役割:
入力:発話履歴 $x_1, x_2, \dots, x_{t-1}$ と交渉シナリオ $c$
出力:返答 $x_t$ の確率分布 -
coarse dialogue act:
$x_t$に対して,coarse dialogue act $z_t$ が設けられている.
例:$x_t$→ “I am willing to pay $15.” $z_t$→ “propose(price=15)”
モジュール型モデルの各定義
-
parser
入力: $x_{t-1}$, 対話履歴 $x_{<t}$, $z_{<t}$, 交渉シナリオ $c$
出力: $z_{t-1}$ - manager
入力: $z_{<t}$,$c$
出力: $z_t$$x_{<t}$ はcoarse dialogue actの決定には影響しない
- generator
入力: $z_t$, $x_{<t}$
出力: $x_t$
3.2 Parser
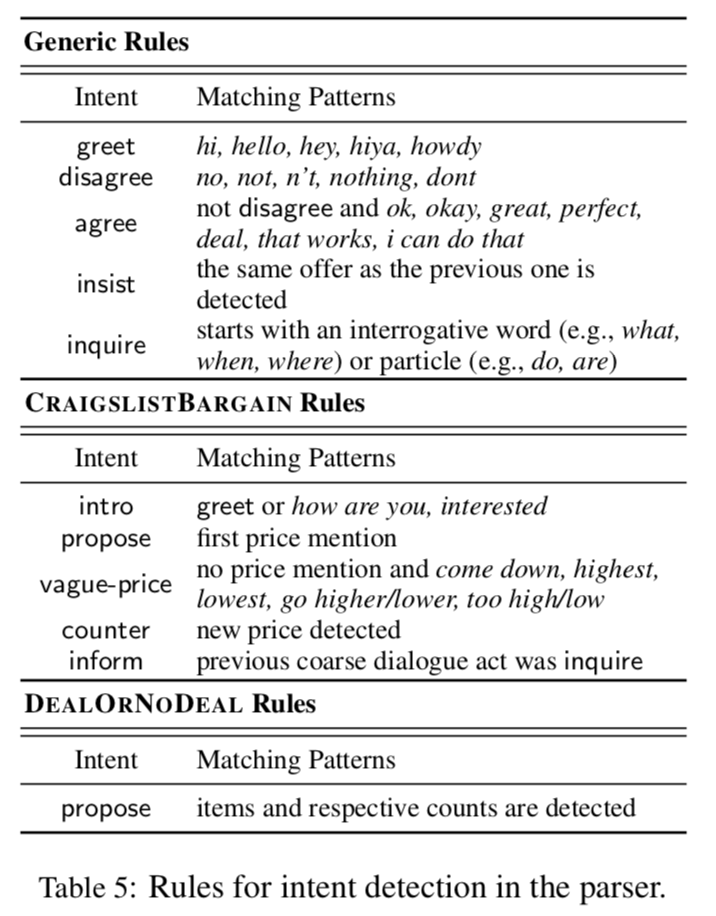
ルールベースのマッチングで,価格や物品に関する情報を抽出する.具体的には,正規表現とif文でマッチングをしているらしい.
図引用: Decoupling Strategy and Generation in Negotiation Dialogues
3.3 Manager
dialogue managerは,各タイムステップ $t$ において,過去のcoarse dialogue acts 履歴 $z_{<t}$ と,交渉シナリオ $c$ から,次に取る行動 $z_t$ を策定する.
Managerの学習手法は,教師あり学習,強化学習,ハイブリッド方式の三つが用いられている.
3.3.1 教師あり学習
人間の振る舞いをモデリングするのに最適な学習手法.
入力: 各学習データは,各対話のcoarse dialogue acts $z_1, \dots. z_T$ からなる.
出力: $p_\theta (z_t | z_{<t}, c)$
学習は学習データの尤度を最大化することで行う. モデルは,通常のseq2seqモデルに注意機構を付加したものである.各dialogue actは,通常のトークンとして入力される.例:offer 150.この場合,語彙数はかなり少なくなる.
3.3.2 強化学習
報酬 $R(z_{1:T})$ をcoarse dialogue actsのひとまとまりに対して適用.3つの報酬関数により実験を行う.
-
Utility
クレイグスリストデータセットでは,ゼロサムゲームとして与える.それ以外のFBのような二者間山分け交渉の場合は,総和となる.クレイグスリストでは,目標価格で購入 or 販売できたときにのみ,効用として,1を獲得でき,それ以外の場合には,0を獲得する
-
Fairness
二者間の効用になるべく差がなくなるようにする.平等重視.計算方法としては,二者間の効用の差で表される. -
Length
長く会話させるための指標.
合意が形成されなかった場合,報酬は一律に$-1$ である. 最適化には,policy gradient(方策勾配法)を用いる.パラメータは以下の式(1)に基づいて更新される.
ただし,$\eta$ は学習率,$b$ は出力の平均から推定されるベースライン.$a_i$ は生成されたトークン(policyが取る行動)を意味しており,$z_{1:T}$に対応している.
- 方策勾配法について
方策勾配法は価値関数 $Q^{\pi_\theta}(s, a)$ を実際に得られた報酬の合計で近似するもの.
ベースラインを設けるのは,期待値の分散を減らすため(variance reduction). これによって,モデルの学習を成功させやすくなるらしい.
3.3.3 Hybrid Policy
coarse dialogue actsが与えられたとき,ドメインに関する知識があれば,ルールベースのmanagerを作成できる.
例:$z_{t-1} = {\rm greet}$ のとき,$z_{t}$ も $\rm greet$ とする.
実用的には,学習済みのmanagerを用いて,意図(行動)を決定させて,それに関する変数は,ルールベースで決定するものである.
3.4 Generator
generatorは,coarse dialogue actと対話履歴の両方に基づいて,検索ベースにより発話内容を決定する.
検索対象の候補はタプルとして保存されている:$(d(x_{t-1}), z_{t-1}, d(x_t), z_t)$
$d$はテンプレート抽出器:”How about $150?”という文があったら,”How about [price]?”と置き換えられる.[price] 部分は生成時に穴埋めされる.
テスト時には,$z_t$ が与えられたら,まず,$z_t$ と $z_{t-1}$ と同じ意図を持つ候補を検索する.候補はテンプレートと現在の対話のコンテキストの類似度で評価される.具体的には,テンプレート $d(x_{t-1})$ はTF-IDFで重み付けされた,BoWベクトルであり,類似度は二つのコンテキストベクトル間の内積で得られる.
4. Experiments
4.1 Models
まず,教師あり学習によってモデルを学習させる.このとき,2種類のモデルを比較する.
-
SL(word): seq2seq + attention
ベクトルはCBoWで埋め込み. -
SL(act): モジュール型のモデル
ルールベースのパーサー,学習済みのmanager,検索ベースのgeneratorからなる.
クレイグスリストデータセットには様々な価格帯があるので,値段を正規化して扱う.(target priceが1,bottomline priceが0.)売り手のbottomlineは,listing priceの0.7倍.買い手のbottomlineはlisting price.
教師あり学習で学習させたモデルを用いて,強化学習でfine-tuneする.モデルの詳細は以下の表6の通り.

図引用: Decoupling Strategy and Generation in Negotiation Dialogues
4.2 実験設定
-
SL(word)
3個前までの発言をattentionの対象にする.交渉シナリオは,CBoWで埋め込み. -
SL(word) / SL(act)の両方
GloVe埋め込み:300次元
2層のLSTM:300次元
パラメータは-0.1から0.1の一様分布で初期化
AdaGrad:(学習率:0.01,バッチサイズ:128)
20エポック学習 -
RL
学習率:0.001
5000エピソード学習
4.3 人間による評価
二つの指標により評価.
-
task specificなスコア
効用・合意案の公平性・発話の長さ・合意率 -
human-likeness
1〜5の5段階評価.高ければ高いほど良い.スコアはAMTのworkerによりつけられた.
表7の意味するところ
-
教師あり学習をつけると人間らしさが向上.ただし,actベースの方がスコアが良い.
-
強化学習をつけると,wordベースのときは人間らしさが低下する.一方で,actベースのときは報酬を最適化しながらも,人間らしさを維持している.

図引用: Decoupling Strategy and Generation in Negotiation Dialogues
前の記事
次の記事