ゼロから作るDeep Learningとともに学ぶフレームワーク(畳み込みニューラルネットワーク編)
はじめに
このシリーズでは、深層学習の入門書として有名な、「ゼロから作るDeep Learning」(以下、ゼロから〜)と同時並行でフレームワークを学習し、その定着を目指します。
前回は、学習に関する様々テクニックについて紹介しました。今回はこれまでの話題とは大きく変わって、畳み込みニューラルネットワーク(CNN)による画像分類に取り組みます。また、CNNのフィルターの重み可視化や、学習済みモデルの転移学習・最近のCNNモデルで使われるテクニックの一端についても紹介します。なお、本稿はゼロから〜の第7章に対応する内容となっています。
参考: ゼロから〜の第7章: P205〜P238
1. CIFAR10 データセット
今回取り組むタスクは、CIFAR10と呼ばれる画像データセットをCNNで分類することです。
CIFAR10は、10個のクラスを持つカラー画像のデータセットとなっていて、MNISTデータセットと同様にKerasで簡単に呼び出せるようになっています。CIFAR10の画像の一部を試しに表示させてみましょう。
from keras.datasets import cifar10
import matplotlib.pyplot as plt
from scipy.misc import toimage
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
n = 3
for i in range(n):
image = toimage(x_train[i])
plt.subplot(1, n, i + 1)
plt.imshow(image)
plt.axis('off')
plt.show()
Output:

出力結果から、大型自動車の画像や、動物のような画像が表示されていることが確認できます。
2. モデルの実装
それでは、CIFAR10を分類するためのCNNモデルの実装をしていきましょう。
今回実装するモデルは、ゼロから〜のP229で扱われているSimpleConvNetに似た構成とします。また、ソースコード名は、cnn.pyとして進めていきます。
例によってモデルの概要図を以下に示します。実装の際の参考にしてください。なお、この図は自作ではなく、GitHubの@yu4uさんらによる「convnet-drawer」により描画しています。CNNであれば簡単に作図できるので、ぜひ使ってみてください。
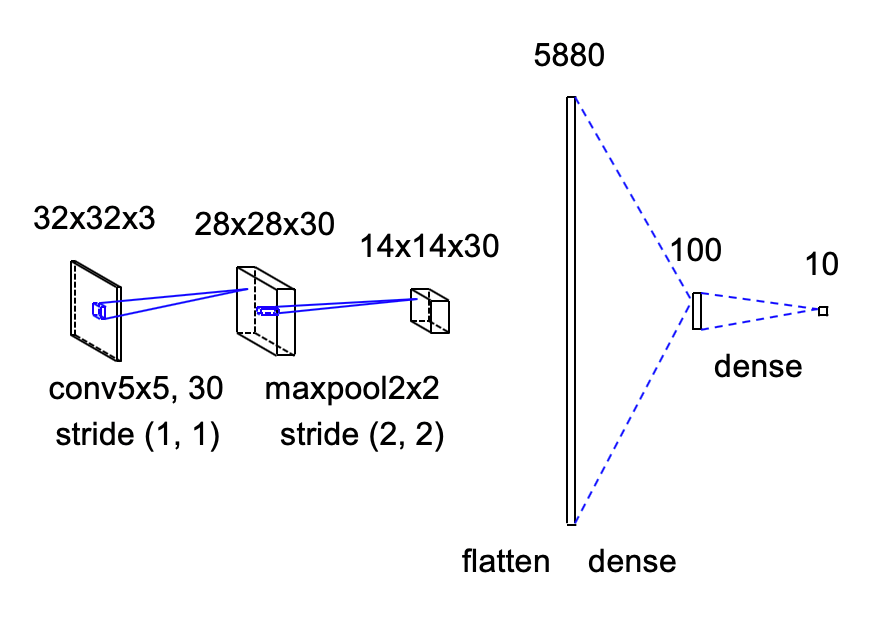
2.1 レイヤーの定義
今回使うモジュールやレイヤーをインポートします。
新たに登場するレイヤーとしては、Conv2D、MaxPooling2D、Flattenが挙げられます。これらのレイヤーについては、以下でそれぞれ解説していきます。
from keras import Model
from keras.layers import Input, Dense, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.datasets import cifar10
from keras.utils import to_categorical
import matplotlib.pyplot as plt
2.2 畳み込み処理
畳み込み処理部のソースコードとその説明を以下に示します。
-
入力部
CIFAR10データセットは、32*32のカラー画像: RGBのデータセットです。
したがって、入力サイズは(32, 32, 3)となります。 -
畳み込み部
画像の畳み込み処理には、Conv2Dレイヤーを活用します。
Conv2Dの主な引数の説明は以下のようになります。引数 説明 filtersフィルターの個数を指定する。
ここで指定するフィルターはそれぞれ異なる重みやバイアスを持つものである。
ゼロから〜では、filter_numとして定義されている。kernel_sizeフィルターのサイズを指定する。
ゼロから〜では、filter_sizeとして定義されている。stridesストライド幅を指定する。
ゼロから〜では、strideとして定義されている。paddingゼロパディングの有無を指定する。 'same'のときには、ゼロパディングが適用され、入力サイズと出力サイズは同じになる。'valid'のときには、出力サイズは入力サイズよりも小さくなる。
ゼロから〜では、padとして定義されている。今回実装する畳み込み層は、ほぼゼロから〜の設定値に基づくので、各値の詳細な説明は省きます。
-
プーリング部
Kerasにおいて画像の最大値プーリングの処理は、MaxPooling2Dで実装できます。MaxPooling2Dの主な引数は、pool_sizeのみです。例えば、2*2のプーリングを行いたい場合には、pool_sizeに2か(2,2)を指定します。
# 入力部
_input = Input(shape=(32, 32, 3))
# 畳み込み部
_hidden = Conv2D(filters=30, kernel_size=5, strides=(1, 1), padding='valid', activation='relu')(_input)
# プーリング部
_hidden = MaxPooling2D(pool_size=(2, 2))(_hidden)
2.3 出力処理
プーリングが終わったら、残るは全結合層に通して、Softmaxで分類するだけです。簡単な気がしますが一つだけ落とし穴があります。
ここで、MaxPooling2Dの出力のテンソルサイズを見てみましょう。最大値プーリングまでのモデルを切り出して確認します。
from keras import Model
from keras.layers import Input
from keras.layers import Conv2D, MaxPooling2D
_input = Input(shape=(32, 32, 3))
_hidden = Conv2D(filters=30, kernel_size=5, strides=(1, 1), padding='valid', activation='relu')(_input)
_hidden = MaxPooling2D(pool_size=(2, 2))(_hidden)
model = Model(_input, _hidden)
model.summary()
Output:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 30) 2280
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 30) 0
=================================================================
Total params: 2,280
Trainable params: 2,280
Non-trainable params: 0
_________________________________________________________________
MaxPooling2Dの出力は、(None, 14, 14, 30)となっていることがわかります。この状態で、Denseレイヤーにこのテンソルを渡すとどうなるか、確認してみましょう。
from keras import Model
from keras.layers import Input, Dense
from keras.layers import Conv2D, MaxPooling2D
_input = Input(shape=(32, 32, 3))
_hidden = Conv2D(filters=30, kernel_size=5, strides=(1, 1), padding='valid', activation='relu')(_input)
_hidden = MaxPooling2D(pool_size=(2, 2))(_hidden)
model = Model(_input, _hidden)
Output:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 30) 2280
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 30) 0
_________________________________________________________________
dense_1 (Dense) (None, 14, 14, 100) 3100
=================================================================
Total params: 5,380
Trainable params: 5,380
Non-trainable params: 0
_________________________________________________________________
なんと、(None, 14, 14, 100)という出力が出てきてしまいました。本来ならば、ここでは出力として(None, 100)が欲しい場面です。
この原因は、KerasのDenseレイヤーの出力の定義が、
nD tensor with shape: (batch_size, …, units)
となっているためで、元の入力のテンソルの次元を変えない仕様になっているのです。
したがって、Kerasで3次元以上のデータを2次元に落とし込みたいときには、事前にReshapeかFlattenなどを用いてテンソルの形状を変更(平滑化)する必要があります。今回の場合、以下のようにすれば望みの出力が得られます。
from keras import Model
from keras.layers import Input, Dense, Flatten
from keras.layers import Conv2D, MaxPooling2D
_input = Input(shape=(32, 32, 3))
_hidden = Conv2D(filters=30, kernel_size=5, strides=(1, 1), padding='valid', activation='relu')(_input)
_hidden = MaxPooling2D(pool_size=(2, 2))(_hidden)
_hidden = Flatten()(_hidden)
_hidden = Dense(100, activation='relu')(_hidden)
_output = Dense(10, activation='softmax')(_hidden)
model = Model(_input, _output)
model.summary()
Output:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 30) 2280
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 30) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 5880) 0
_________________________________________________________________
dense_1 (Dense) (None, 100) 588100
_________________________________________________________________
dense_2 (Dense) (None, 10) 1010
=================================================================
Total params: 591,390
Trainable params: 591,390
Non-trainable params: 0
_________________________________________________________________
なお、Flattenはその名の通り、入力のテンソルを平らにする(平滑化する)レイヤーです。
2.4 データセットの読み込みと学習設定
この部分は前回までとほぼ同一なので、説明は省きます。以下にソースコードを示すので、上のソースコードと合わせて動かしてみてください。
(注意) 畳み込みニューラルネットの学習は、普通のパソコンで回すとそれなりの時間を要します。(手持ちのノートPCでは、エポックあたり30秒程度かかりました。)また、初めて動かすときには、CIFAR10データセットのダウンロード処理に数分を要します。
from keras.datasets import cifar10
from keras.utils import to_categorical
# データセットの読み込み
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float') / 255.
x_test = x_test.astype('float') / 255.
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
# 学習設定
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
_results = model.fit(x=x_train, y=y_train, batch_size=100, epochs=20, verbose=1, validation_data=(x_test, y_test))


3. 実験
3.1 1層畳み込みニューラルネットの学習結果
上記で実装したcnn.pyを動作させた結果、以下のような分類精度の推移となりました。
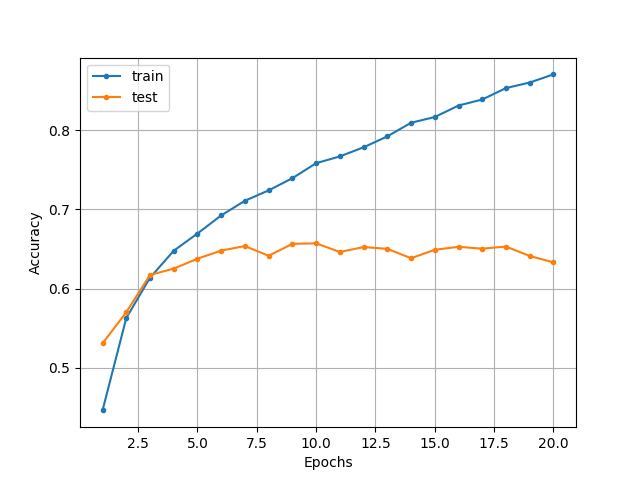
5エポック目あたりから過学習の傾向が見られます。また、テストデータでの最高精度は65%程度であることが読み取れます。
10クラスの分類で65%の精度なので、デタラメに分類しているわけではなさそうです。そこで、次節ではゼロから〜のP234と同様に、CNNのフィルターの重みを可視化することで、規則性のあるフィルターを学習できているかどうかを確認してみることにします。
参照: (GitHub: cnn.py)
3.2 重みの可視化
3.2.1 重み画像の生成
CNNの重みを可視化するには、model.get_weights()でパラメータのリストを取得して、そのリストに少し手を加える必要があります。
本シリーズの第2弾で確認したように、パラメータのリストはモデルの入力側から順に登録されています。したがって、今回のモデルでは、畳み込み層のフィルターの重みは先頭に格納されていることになります。
その点を踏まえて、次のCNNのフィルターの重みを可視化するスクリプト抜粋をみてください。このスクリプトは、weight_imageというリストに各フィルタの重みのNumPy配列を追加していくものになっています。
import numpy as np
from keras.preprocessing.image import array_to_img
weights = model.get_weights()
weights = weights[0] # 畳み込み層の重みを取ってくる
weights = np.split(weights, 30, axis=3) # 各フィルターに分割する
weight_image = []
for weight in weights:
weight = np.squeeze(weight, axis=3)
weight = array_to_img(weight)
weight = np.array(weight)
weight_image.append(weight)
簡単に各部を説明していきます。まず、np.split()により、(5, 5, 3, 30)となっている重みのリストを、(5, 5, 3, 1)の形を持つ30個のリストに分割します。
その後、np.squeeze()により、無駄な次元: 3次元目をなくします。これにより、(5, 5, 3)の形状を持つリストが得られます。
最後にarray_to_image()を用いてリストをPIL形式の画像に変換し、タイル状に画像を並べるために再びNumPy形式に変換し直して、リストに追加しておきます。
3.2.2 タイル状に画像を表示
残るはweight_imageを画像化すれば良いだけですが、どうせならタイル状に並べて表示したいところです。しかし、タイル状に複数画像を出力するのは若干手間がかかります…
以下に、タイル状に画像を表示するサンプルスクリプトを示します。各部の詳しい説明は省きますが、大まかには空の生成画像サイズのリストを用意して、そこに元のピースとなる画像を入れていく流れになります。
import math
from PIL import Image
img = combine_images(np.array(weight_image)) # 重み画像の合体
Image.fromarray(img.astype(np.uint8)).save('weight.png')
def combine_images(images):
num = images.shape[0]
width = int(math.sqrt(num))
height = int(math.ceil(float(num) / width))
shape = images.shape[1:]
image = np.zeros((height * shape[0], width * shape[1], shape[2]),
dtype=images.dtype)
for index, img in enumerate(images):
i = int(index / width)
j = index % width
image[i * shape[0]:(i + 1) * shape[0], j * shape[1]:(j + 1) * shape[1], :] = img
return image
上のスクリプトで重み画像を可視化した結果が以下の図です。

<重みの可視化結果>
重みの可視化結果の図から、学習前は完全にランダムな重みとなっているフィルタが、学習後にはある特定の方向に反応するフィルタとして変化していることがわかります。したがって、本来の目的である、規則性のあるフィルターを学習できていることが確認できました!
なお、一連のソースコードについては、visualize_weights.pyとしてGitHubに置いてあります。参考にしてください。
4. 学習済みモデルの活用
今回実装してきた1層のCNNでは、CIFAR10で65%程度の分類精度しか出せませんでした。満足に写真の分類をできるようになるには程遠いですね。
分類精度をより向上させるにはモデルの構造を改良することも考えられますが、手っ取り早いのは、学習済みモデルを活用して転移学習を行うことです。ここでは一例として、Kerasが学習済みモデルとして提供しているMobileNetを用いて、転移学習によるCIFAR10データセットの分類実験をして、どれほど高い分類性能が記録されるかを検証していこうと思います。
4.1 MobileNetの特徴
MobileNetはその名の通り、学習が速い&軽いという特徴を持ち、それなりの分類精度を誇るモデルです。学習はImageNetという画像データベースを用いて行っています。
今回MobileNetを扱った理由は、各自のパソコン上でも現実的に動作可能な学習済みモデルであるためです。モデルの詳細を知りたい方は、下記のリンクより論文を確認してみてください。
参考: (ImageNetの公式サイト)
参考: (MobileNetの論文)
4.2 MobileNetの読み込み
では、Kerasで実際にMobileNetを活用したモデルを構築してみましょう。
MobileNetモデルの読み込みは非常に簡単で、下記に示すように1行で読み込めます。
MobileNetの引数については、include_topは出力層も含めたモデルにするかどうかを指定し、poolingについては出力層を含めないモデルのときに、プーリングの有無やその種類を指定します。今回は10クラス分類のため、出力層を含めないモデルとし、プーリングには次章で説明する「Global Average Pooling」を指定しました。
from keras.applications.mobilenet import MobileNet
from keras import Model
from keras.layers import Input, Dense
_input = Input(shape=(32, 32, 3))
_hidden = MobileNet(include_top=False, pooling='avg')(_input)
_output = Dense(10, activation='softmax')(_hidden)
model = Model(_input, _output)
model.summary()
Output:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
mobilenet_1.00_224 (Model) (None, 1024) 3228864
_________________________________________________________________
dense_1 (Dense) (None, 10) 10250
=================================================================
Total params: 3,239,114
Trainable params: 3,217,226
Non-trainable params: 21,888
_________________________________________________________________
4.3 データセットの読み込み
MobileNetは入力サイズとして、(224, 224, 3)を想定していますが、Kerasのドキュメントを見ると、幅と高さが32以上であれば良いと書いてあります。そのため、今回に限っては特にリサイズすることなく、CIFAR10の画像データをそのままモデルに入力することができます。
from keras.datasets import cifar10
from keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float') / 255.
x_test = x_test.astype('float') / 255.
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
4.4 転移学習の実行
転移学習を実行する前に、evaluateメソッドを使って学習前のモデルの精度を確認しておこうと思います。
# 学習設定
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 事前学習済みモデルのテスト
print(model.evaluate(x=x_test, y=y_test, batch_size=128))
Output:
10000/10000 [==============================] - 2s 211us/step
[2.3138149349212647, 0.1194]
出力からわかるように、精度は11.9%でした。出力層の学習が全くできていない状態なので、このような結果となったと考えられます。
では、転移学習なので数エポック回すだけで事足りるため、今回は3エポックだけ回して精度の推移を見ていくことにします。
# 転移学習してみる
_results = model.fit(x=x_train, y=y_train, batch_size=128, epochs=3, verbose=1, validation_data=(x_test, y_test))
Output:
Train on 50000 samples, validate on 10000 samples
Epoch 1/3
50000/50000 [==============================] - 17s 344us/step - loss: 1.0968 - acc: 0.6426 - val_loss: 0.9881 - val_acc: 0.7144
Epoch 2/3
50000/50000 [==============================] - 15s 307us/step - loss: 0.6443 - acc: 0.7826 - val_loss: 0.7400 - val_acc: 0.7499
Epoch 3/3
50000/50000 [==============================] - 16s 314us/step - loss: 0.5114 - acc: 0.8265 - val_loss: 0.7199 - val_acc: 0.7728
2エポック目の時点で、val_accが74.99%とほぼ10%精度が向上していることがわかります。やはり、転移学習を用いることで、省コストでそれなりの精度を出せる分類器を手に入れられるメリットは大きいと感じます。
ソースコードは、transfer_learning.pyとして、GitHubに置いてあります。
5. 最近のCNN
最後に簡単ですが、ゼロから〜には書かれていないCNN関連のテクニックについて触れていきたいと思います。
5.1 Global Average Pooling
Global Average Pooling(以下、GAP)は出力側の全結合層を置き換えるものとして活用されています。このメリットとしては、過学習を防ぎつつ、モデルのパラメータ数を減らすことができる点が挙げられます。
GAPでは、各チャンネルごとにその特徴マップの値を平均した値を出力値とします。つまり、畳み込み&プーリング処理後のテンソルの形状が、(None, 14, 14, 30)であったとき、GAPを適用すると、(None, 30)となります。論文によると、各出力の特徴マップは、分類カテゴリの”confidence map”として容易に解釈できるとされています。
KerasでGAPを適用するのは非常に簡単であり、keras.layersにある、GlobalAveragePooling2Dレイヤーをインポートして使うだけです。
以下に、cnn.pyにGAPを適用したモデルのスクリプトを示します。このモデルでは、最大値プーリングと全結合層の間にGAPを配置しています。
from keras import Model
from keras.layers import Input, Dense
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D
# モデル定義
_input = Input(shape=(32, 32, 3))
_hidden = Conv2D(filters=30, kernel_size=5, strides=(1, 1), padding='valid', activation='relu')(_input)
_hidden = MaxPooling2D(pool_size=(2, 2))(_hidden)
_hidden = GlobalAveragePooling2D()(_hidden)
_hidden = Dense(100, activation='relu')(_hidden)
_output = Dense(10, activation='softmax')(_hidden)
model = Model(_input, _output)
model.summary()
Output:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 30) 2280
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 30) 0
_________________________________________________________________
global_average_pooling2d_1 ( (None, 30) 0
_________________________________________________________________
dense_1 (Dense) (None, 100) 3100
_________________________________________________________________
dense_2 (Dense) (None, 10) 1010
=================================================================
Total params: 6,390
Trainable params: 6,390
Non-trainable params: 0
_________________________________________________________________
出力結果より、cnn.pyでは、総パラメータ数が591,390であったのに対し、GAPを適用したモデルでは、6,390とかなり減少していることが実際に確認できます。
ちなみにこのモデルを学習させた結果が以下の図のようになります。
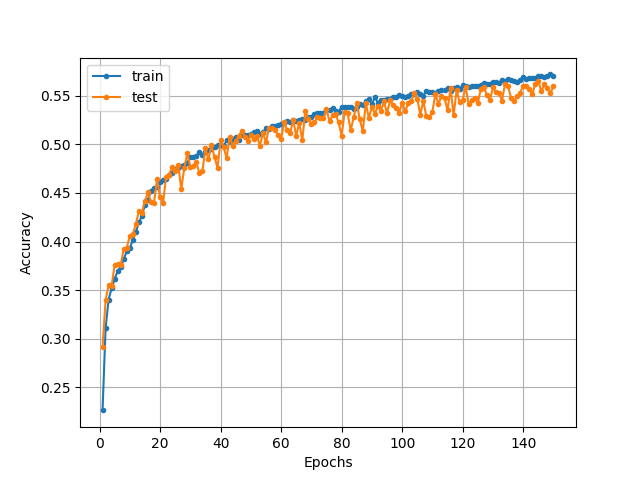
150エポック回して、分類精度は56%程度となりました。チューニング等一切していないので、元のモデルよりも、10%程度下がってしまっていますね…なお、この例のようにGAPを適用したモデルは一般に学習が遅くなるというデメリットが報告されているので、ご注意ください。
参考: (KerasのGlobal Average Poolingのドキュメント)
参考: (GAPの原著論文)
参照: (GitHub: cnn_with_gap.py)
5.2 CNNのサーベイ記事
CNNに関する研究のより詳しい流れについては、若干古くなっていますが、かなり充実したまとめがあるので、以下のリンクを参考にすると良いと思います。
まとめ
今回は、畳み込みニューラルネットワーク(CNN)について触れていきました。Global Average Poolingは単に一般物体認識だけでなく、深層生成モデルの分野でも使われる重要なテクニックです。また、前回までに登場したドロップアウトやバッチ正規化もよくCNNで使われる手法であることは、間違いないです。今後、GAPと合わせて意識しておくと良いかもしれません。
これにて、ゼロから〜とともに学ぶKerasシリーズは完結となりますが、本シリーズで少しでも深層学習フレームワークに慣れる一助となっていたら幸いです。
今後は少し期間を置いて、自然言語処理の入門のための記事などを投稿できたらと思っています。
ソースコード
ソースコードは、GitHubより入手できます。