ゼロから作るDeep Learningとともに学ぶフレームワーク(ニューラルネットワークの学習編)
はじめに
このシリーズでは、深層学習の入門書として有名な、「ゼロから作るDeep Learning」(以下、ゼロから〜)と同時並行で、フレームワークを学習し、その定着を目指します。
前回までは、3層のニューラルネットワークをKerasで実装し、推論処理のみを扱ってきました。今回からは、ゼロから〜の4章と5章に対応する、ニューラルネットワークの学習にとりかかります。また、同時に実験結果の簡単な可視化方法についても触れていきます。
では、2層のニューラルネットワークを題材にMNISTの分類モデルをKerasで実装し、学習させてみましょう!
1. プロジェクトの作成
はじめに、2層ニューラルネットワーク用のプロジェクトを作成してください。
以下、本投稿ではtwo_nn.pyを作成するものとして進めます。
2. 実装
2.1 モデルの概要
-
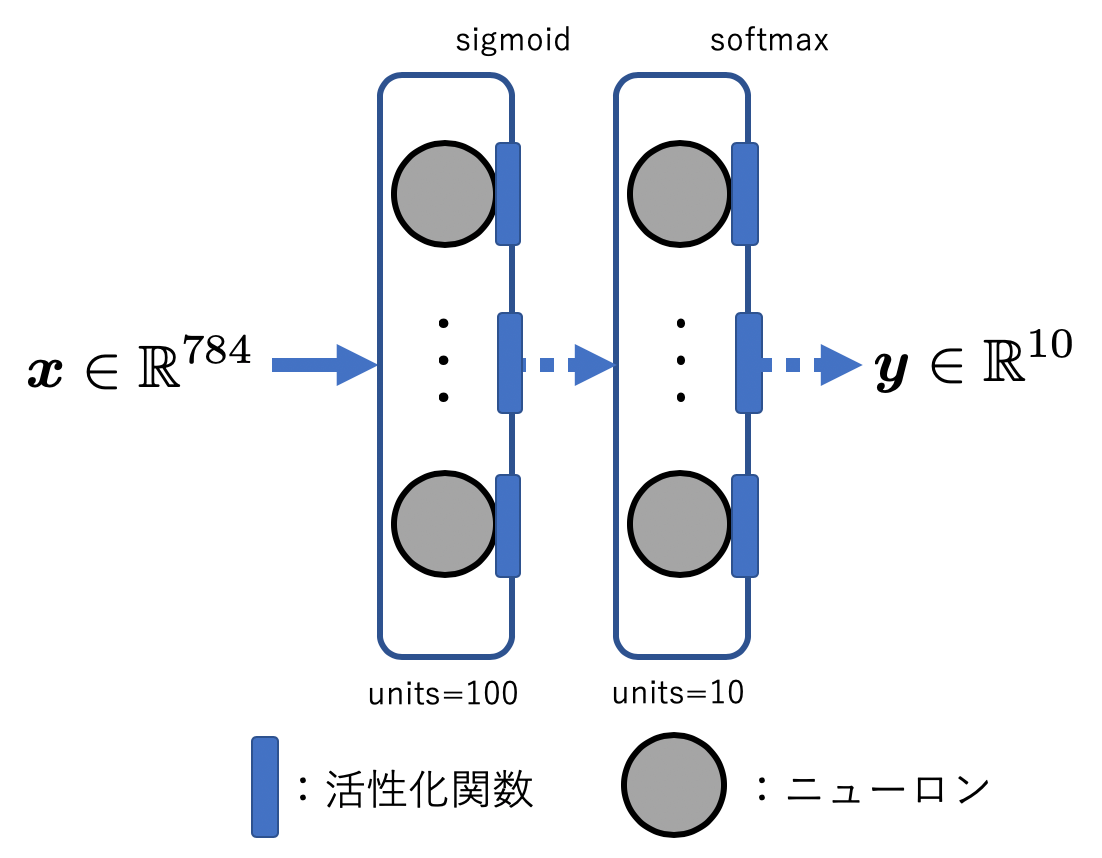
今回実装するモデルの概要図を以下に示します。実装の参考にしてください。
-
MNISTデータセットの分類を行うモデルを学習させるので、出力はクラスの数に合わせて10次元のベクトルとなっています。
2.2 モデルの実装
-
ゼロから〜の第4章に対応する2層ニューラルネットワークをKerasで実装していきます。
-
モデルの実装は前回とあまり変わらないので、以下に一気に進めてしまいます。
復習として、ソースコードを読んで理解できるかを確認すると良いと思います。 -
モデルのパラメータ等は全てゼロから〜のP117〜122に基づいています。
from keras import Model
from keras.layers import Input, Dense
# パラメータ
img_shape = (28 * 28, )
hidden_dim = 100
output_dim = 10
# モデルを定義する
_input = Input(shape=img_shape)
_hidden = Dense(hidden_dim, activation='sigmoid')(_input)
_output = Dense(output_dim, activation='softmax')(_hidden)
model = Model(inputs=_input, outputs=_output)
model.summary()
Output:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 784) 0
_________________________________________________________________
dense_1 (Dense) (None, 100) 78500
_________________________________________________________________
dense_2 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
2.3 データの読み込み
-
前回と同様にMNISTデータセットを読み込み、前処理(正規化、データの整形)を行います。
-
前回との相違点としては、ラベルデータを学習のためにone-hotベクトルに変換させる点です。
- one-hotベクトル化は、
to_categoricalを用いることで行えます。
引数は変換元リストとクラス数です。戻り値は変換後のリストです。
- one-hotベクトル化は、
# データを読み込む
from keras.datasets import mnist
from keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float') / 255.
x_test = x_test.astype('float') / 255.
print(f'Before: {y_train.shape}')
y_train = to_categorical(y_train, num_classes=output_dim)
print(f'After: {y_train.shape}')
print(f'y_train[0]: {y_train[0]}')
y_test = to_categorical(y_test, num_classes=output_dim)
Output:
Before: (60000,)
y_train[0]: 5
After: (60000, 10)
y_train[0]: [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
しっかりと、ラベルがone-hotベクトルに変換されていることが確認できます。
2.4 学習の設定
ここからが本格的に新しい部分になります。
-
設計したモデルで学習を実行できるようにするために、「損失関数」と「最適化アルゴリズム」を設定します。
- 損失関数と最適化アルゴリズムの設定は、
compileメソッドで行えます。-
ゼロから〜の4章の実装では、損失関数にクロスエントロピー、最適化アルゴリズムに確率的勾配降下法が用いられています。
したがって、本実装でもlossに'categorical_crossentropy'を指定し、optimizerにSGD(lr=learning_rate)を指定します。 -
ゼロから〜で使われている学習率は
0.1であるため、Kerasのデフォルト値0.01と異なります。そのため、SGDに学習率を渡す必要があります。
-
- 評価関数の設定も行います。
ゼロから〜のP121では、認識精度を評価関数としているので、compileメソッドの引数:metricsに['accuracy']を指定します。
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.1), loss='categorical_crossentropy', metrics=['accuracy'])
参照: (Kerasで利用可能な損失関数について)
参照: (Kerasで利用可能な最適化アルゴリズムについて)
参照: (Kerasにおける評価関数について)
(注意) Kerasをはじめとする深層学習フレームワークでは、ユーザが順伝播の計算グラフを構築すると、フレームワークが自動的に逆伝播用の処理をブラックボックス的に行ってくれます。 したがって、ゼロから〜の5章の部分は、フレームワーク使用時には実装する必要がありません。(自分でレイヤーを設計することがない限り。)


3. モデルの学習
それでは、モデルの学習を進めていきましょう。
- モデルの学習は、
fitメソッドで行います。
以下に各引数について簡単に対応表を示します。
| 引数 | 説明 |
|---|---|
x |
訓練データを指定します |
y |
訓練データに対応するラベルデータ(正解ラベル)を指定します |
batch_size |
ミニバッチのサイズを指定します |
epochs |
エポック数(学習回数)を指定します |
verbose |
学習進捗をどのように表示するか設定します |
validation_data |
テストデータを指定します |
-
fitメソッドの戻り値は、Historyオブジェクトになっています。
この戻り値を活用することで、損失関数や認識精度のプロットができます。 -
validation_dataにテストデータを与えることで、エポックごとにモデルのテスト精度を測ることができます。
epochs = 17
_results = model.fit(x=x_train, y=y_train, batch_size=100, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
Output:
Epoch 1/17
60000/60000 [==============================] - 2s 31us/step - loss: 0.8805 - acc: 0.7994
Epoch 2/17
60000/60000 [==============================] - 2s 27us/step - loss: 0.4102 - acc: 0.8907
~~~
~~~
Epoch 17/17
60000/60000 [==============================] - 2s 27us/step - loss: 0.1771 - acc: 0.9497
4. 学習結果の表示
ゼロから〜のP119とP121では、それぞれ損失関数の値と認識精度の推移を図にしているので、ここでも実際に図にしてみましょう!
4.1 損失関数の値の推移
Pythonの図表描画ライブラリである、Matplotlibを活用して、損失関数の値の推移を図にします。
4.1.1 Matplotlibのインストール
Matplotlibをインストールしていない方は、インストールしましょう。
pip install matplotlib
(注意)macOSでMatplotlibをインポートすると、バックエンドの問題でエラーが発生することがあります。その場合は、下記を参照してバックエンドを書き換えてください。
4.1.2 Historyオブジェクトの中身
fitメソッドの戻り値は、Historyオブジェクトであると前章で紹介しました。
実験結果を可視化するためにも、Historyオブジェクトの中身を確認しておきましょう。
print(f'Keys: {_results.history.keys()}')
Output:
Keys: dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
このように、損失関数の値と認識精度の結果が訓練・テストデータともに格納されていることがわかります。
4.1.3 プロットしてみる
Historyオブジェクトから訓練時とテスト時の損失関数の値のリスト受け取り、それらをプロットします。
一連のソースコードを下記に示します。
なお、Matplotlibの詳しい使い方については、公式チュートリアルをご覧ください。
import matplotlib.pyplot as plt
loss = _results.history['loss']
val_loss = _results.history['val_loss']
plt.figure()
plt.plot(range(1, epochs+1), loss, marker='.', label='train')
plt.plot(range(1, epochs+1), val_loss, marker='.', label='test')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.savefig('loss.png')
Output:
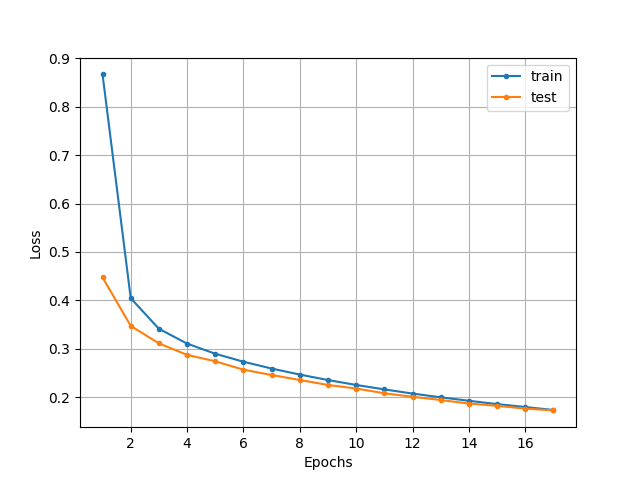
きちんと損失関数がプロットされていることが確認できました!
4.2 認識精度の推移
モデルが過学習していないかを認識精度の推移を図にして確認してみましょう!
プロットの流れは、損失関数の時とほとんど同一のため、説明は割愛します。
以下にソースコードを貼るので、各自試してみてください。
plt.clf()
acc = _results.history['acc']
val_acc = _results.history['val_acc']
plt.plot(range(1, epochs+1), acc, marker='.', label='train')
plt.plot(range(1, epochs+1), val_acc, marker='.', label='test')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.savefig('acc.png')
plt.close()
Output:
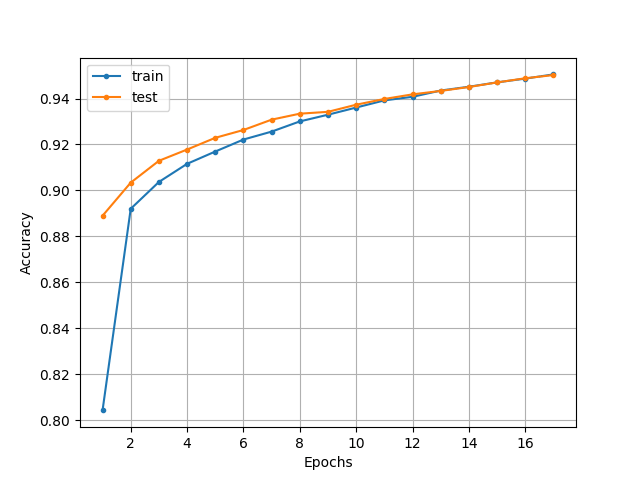
図から、テストデータの認識精度を訓練データの認識精度が大幅に上回る現象は確認できないので、モデルの過学習は起きていないことがわかります。
まとめ
今回はニューラルネットワークの学習について扱いました。
フレームワークを活用することで、誤差逆伝播が自動で実行されるため、順伝播の処理だけ記述すればよいという大きなメリットを体感できたと思います。
次回は、ゼロから〜の第6章に対応する、「学習に関するテクニック」をKerasを用いて実証していきたいと思います。
ソースコード
ソースコードは、GitHubにて公開しています。